Les métiers de la data à connaître en 2026

Au sein des équipes IT, la chaîne de valeur s’étend désormais de l’ingestion brute jusqu’au déploiement de modèles en production, avec monitoring, observabilité et gouvernance intégrés dès la conception. Les entreprises ne recrutent plus un Data Scientist générique : elles ciblent des rôles précis, ancrés dans une architecture, une stack et un contexte métier déterminés. Comprendre ces rôles, leurs responsabilités réelles et leurs passerelles de carrière change radicalement la manière d’aborder le marché. Tour d’horizon des huit métiers data qui dessinent l’architecture humaine des plateformes modernes !
Les métiers data qui comptent vraiment en 2026
1️⃣ Data Analyst
Le Data Analyst transforme une question métier floue en métriques robustes, analyses exploitables et décisions actionnables.
Pas de « jolis graphiques ». Une structuration rigoureuse de la réalité business.
Il s’insère entre transformation et exposition. Interface directe avec produit, marketing, finance ou opérations.
Stack typique :
BI (Looker, Power BI, Tableau…)
Modélisation analytique
Git / versioning métrique
Documentation structurée
Passerelles :
Vers Analytics Engineer (dimension technique accrue)
Vers Product Analytics
Vers Data Science (si appétence modélisation)
2️⃣ Analytics Engineer
Pourquoi ce rôle explose ?
Le succès de ce rôle tient en un mot : dbt.
En effet, ce profil occupe un territoire longtemps ignoré : l’ingénierie appliquée à l’analytique. Il reprend les bonnes pratiques du dev (test, CI/CD, versioning, review, documentation) et les applique à la modélisation SQL dans l’entrepôt de données.
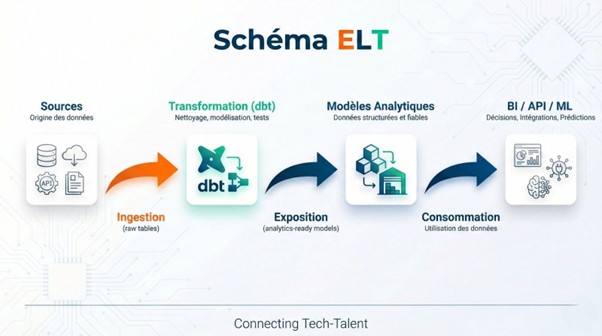
En 2026, l’Analytics Engineer :
transforme les données brutes en datasets prêts à l’analyse ;
structure les modèles de données (ex. : modèle en étoile ou snowflake) ;
documente chaque colonne ;
définit des conventions claires (naming, ownership, granularité) ;
écrit des tests unitaires (null, unique, relationnels) ;
surveille la fraîcheur des données critiques.
Il devient, de facto, le gardien du semantic layer.
Passerelles :
Vers Data Engineer (logique plateforme)
Vers Product Analytics Lead
Vers Data Architect (si gouvernance & scalabilité)
3️⃣ Data Engineer

Le rôle « plomberie » qui conditionne tout le reste
Pas de données exploitables sans pipeline robuste. Le Data Engineer construit les chemins, surveille les débits, détecte les fuites.
Il orchestre l’ingestion de données depuis des dizaines de sources, conçoit les pipelines de traitement, optimise la latence et surveille la consommation de ressources cloud.
Sa responsabilité ne se limite pas au code qui tourne : il garantit la fiabilité, la scalabilité et la maintenabilité de la stack. Il anticipe les pannes, trace les transformations, versionne les jobs.
Stack typique :
Python / Spark / SQL
Orchestration (Airflow, Prefect, Dagster)
Data warehouse / lakehouse (Snowflake, BigQuery, Redshift, Databricks…)
Cloud (AWS, GCP, Azure)
Tests automatisés, monitoring (Great Expectations, Monte Carlo)
Terraform / IaC
Passerelles :
Vers MLE (via la production de données modélisables)
Vers Architecte (design de plateforme)
Vers Analytics Engineer (si affinité SQL / BI)
4️⃣ Data Architect
L’architecte des choix structurants
Il ne code pas les pipelines, mais il décide comment les équipes les construisent.
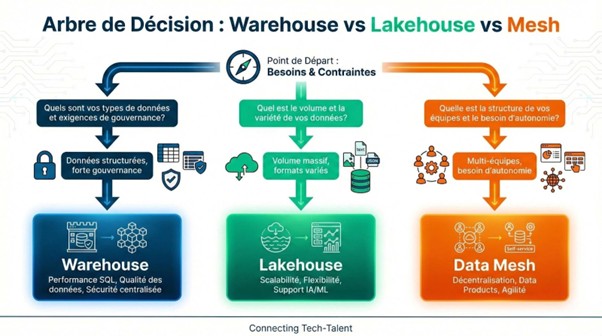
Le Data Architect conçoit l’architecture cible : data lake ou lakehouse ? Warehouse centralisé ou mesh décentralisé ? Quelle stratégie d’organisation des datasets ? Quel niveau de sécurité ? Quelle gouvernance technique ?
Ses décisions influencent durablement la maintenabilité, la qualité, les coûts et la rapidité des projets data.
C’est la boussole technico-stratégique.
Stack typique :
Outils Cloud (GCP/AWS/Azure)
Data warehouse / lakehouse
Patterns (Lambda, Kappa, Mesh…)
Catalogues de données / lineage
Sécurité (IAM, chiffrement, audit)
Métriques coûts/performance
Passerelles :
Vers CDO (stratégie globale)
Vers Head of Data (pilotage transverse)
Vers ingénierie si retour au delivery
5️⃣ Data Scientist
Le Data Scientist ne vend pas du rêve. Il conçoit des expériences robustes, entraîne des modèles rigoureux et démontre leur intérêt de manière quantifiable.
Causalité, pas simple corrélation. Impact mesuré, pas « intuition confirmée ».
Il explore, modélise, valide… et supprime ce qui ne fonctionne pas !
Stack typique :
Python / pandas / scikit-learn
SQL / warehouse
MLflow, notebooks, JupyterHub
Librairies stats / causal inference
A/B testing frameworks
Feature stores
Passerelles :
Vers MLE (production)
Vers Product Analyst (plus proche métier)
Vers AI Engineer (si appétence dev)
6️⃣ Machine Learning Engineer

Là où les modèles gagnent (ou meurent)
Le MLE est celui qui met en prod, pour de vrai.
Il transforme un notebook expérimental en système robuste, monitoré, versionné, sécurisé.
Il gère les cycles de vie, les pipelines d’entraînement, le drift, la performance en inference, les contraintes légales.
Sans lui, le modèle reste une démo.
Stack typique :
Python, MLflow, scikit-learn / XGBoost
CI/CD ML (GitHub Actions, Jenkins)
Orchestration : Airflow, Kubeflow
Docker / Kubernetes
Monitoring (drift, latence)
Feature store, model registry
Passerelles :
Vers AI Engineer (si produit & LLM)
Vers Data Engineer (focus pipelines)
Vers Architecte (design scalable)
7️⃣ AI Engineer / LLM Engineer
Le métier « frontline » des produits IA
L’AI Engineer s’éloigne des modèles from scratch. Il compose avec l’existant, l’intègre, le module, l’évalue.
Son terrain de jeu : modèles pré-entraînés, LLM, architectures RAG, agents, serveurs d’inférence, budget tokens, règles de sécurité.
Ce rôle s’impose dans les équipes produit tech. Son objectif : livrer une fonctionnalité IA fiable, explicable, scalable.
Stack typique :
LLM APIs (OpenAI, Claude, Mistral, Cohere…)
RAG (LangChain, LlamaIndex, Weaviate, ChromaDB…)
Embeddings / vector search
Prompt engineering, évaluation, guardrails (Rebuff, NeMo Guardrails)
CI/CD + observabilité IA (LangSmith, Arize Phoenix…)
Python, API REST/GraphQL
Passerelles :
Vers MLE (si focus pipeline / infra)
Vers Product / Head of AI
Vers Architecte (design plateforme LLM)
8️⃣ Data Governance Manager
La data à l’échelle : gouverner sans bloquer
Lorsque plusieurs équipes manipulent des données, les problèmes ne viennent pas du SQL.
Ils viennent des définitions floues, des métriques divergentes, des accès incohérents, des responsabilités mal assignées.
Le rôle de Data Governance Manager consiste à poser un cadre clair, partagé, opérationnel.
Glossaire métier, politiques d’usage, droits d’accès, RGPD, minimisation, lineage, qualité.
Ce n’est pas une posture juridique. C’est un travail d’interface entre l’IT, la data et les métiers.
Stack typique :
Data catalog (Collibra, Atlan, DataGalaxy…)
Lineage tools
Documentation centralisée
Rôles : Data Owner, Data Steward
Accès conditionnés (IAM, policies)
Conformité (DPO, audit, SLA données)
Passerelles :
Vers Architecte (gouvernance infra)
Vers Head of Data
Vers DPO / RSSI (focus privacy)
3 familles structurent réellement le marché

Derrière la diversité des intitulés, trois grandes dynamiques dominent. Chacune correspond à une logique opérationnelle distincte.
1- Build - Plateforme & flux
Ici, l’enjeu porte sur la robustesse technique.
Ingestion fiable. Pipelines versionnés. Orchestration maîtrisée. Warehouse optimisé. Coûts contrôlés.
Compétences typiques :
Orchestration (Airflow, Dagster…)
ELT/ETL
SQL avancé
Infrastructure as Code
Observabilité data
Optimisation requêtes / partitions
On ne parle pas de visualisation. On parle de débit, latence, SLA.
2- Explain - Analytics & décision
La donnée devient langage décisionnel. Définition de KPI cohérents. Modélisation analytique. Construction de dashboards fiables. Exploration ad hoc. Analyse causale.
Les compétences clés comprennent le SQL analytique, la modélisation en étoile, la BI / semantic layer, les métriques versionnées et la culture produit.
3- Predict - IA, ML, LLM
La donnée nourrit un modèle. Le modèle génère une prédiction ou une génération. Les principales composantes sont l’entraînement, la validation, la mise en production, le monitoring du drift, l’optimisation des coûts d’inférence...
Tendances 2026+
L’effet LLM : accélération massive, contraintes décuplées
Les modèles génératifs ont tout bouleversé. Stack, budget, méthodes, livrables : aucun métier data n’échappe à la secousse.
Avant, on entraînait un modèle supervisé, on mesurait ses performances avec des métriques classiques (AUC, F1, RMSE), et l’infra tournait en batch.
Aujourd’hui, on orchestre des prompts, on contextualise, on génère, on évalue subjectivement. L’usage est massif, en temps réel, souvent en production dès le premier jour.
La mesure de la qualité ? Fragmentée.
Le coût ? Variable, parfois opaque.
La sécurité ? À repenser de bout en bout.

Régulation, souveraineté, gouvernance by design
RGPD. IA Act. DSA. DMA. Les acronymes pleuvent, et avec eux, des exigences bien concrètes.
Dès 2026, impossible de concevoir un système data sans intégrer la conformité dès le design.
Concrètement, chaque équipe data doit pouvoir démontrer :
la minimisation des données collectées (fin des logs « juste au cas où »)
la traçabilité du consentement utilisateur
les droits d’accès, d’effacement et de portabilité
une politique claire de conservation limitée
un chiffrement actif des données sensibles, cloisonnées par défaut
Les data owners deviennent responsables de ces exigences. Pas juste le DPO.
Data produit : mettre fin au chaos des KPI contradictoires
Fini le débat sans fin sur « le bon chiffre ». Les organisations data matures passent à la vitesse supérieure.
Elles adoptent :
un semantic layer partagé, versionné, centralisé
un metrics store (type dbt metrics ou Transform)
des jeux de données prêts à l’emploi, exposés en self-serve via API ou BI
des définitions unifiées, avec owner, source et logique métier documentées
Ce que les recruteurs data regardent vraiment
Les buzzwords ne suffisent plus. Un beau profil n’impressionne pas. Un profil qui produit, oui.
Voici ce qui déclenche une prise de contact (ou non) côté recruteur :
Une production concrète : modèle déployé, dashboard utilisé, pipeline monitoré
Des signaux forts de qualité : tests, logs, documentation, alerting
Une posture d’ownership : domaine maîtrisé, responsabilités claires
Une communication métier : impact chiffré, gains mesurés, décisions influencées
Une vision transverse : de la collecte à l’usage, pas un silo
Curieux de savoir où ces profils sont réellement demandés en ce moment ?
→ Explorez toutes les offres data référencées sur notre portail







Commentaire
Connectez-vous ou créez votre compte pour réagir à l’article.