Scaling horizontal : comment ça marche et quand l'utiliser

Ajouter des machines plutôt que d'en grossir une : sur le papier, le scaling horizontal promet une croissance presque sans limite. Le discours séduit, et il n'a pas tort. Mais réduire le scale-out à un simple empilement de serveurs revient à confondre la partie facile avec le vrai travail. Cloner un serveur web, n'importe qui le fait en une après-midi. Faire en sorte que dix nœuds se comportent comme un seul système cohérent, fiable, qui ne s'effondre pas au premier pic : voilà le métier.
Qu'est-ce que le scaling horizontal ?

Le principe : au lieu de muscler une machine unique, on en ajoute plusieurs, identiques, qui se partagent la charge.
On parle de scale-out, par opposition au scale-up vertical. Là où le vertical pousse les murs d'une seule maison, l'horizontal construit un lotissement.
Le chef d'orchestre de ce lotissement, c'est le répartiteur de charge. Il reçoit le trafic et le distribue entre les nœuds disponibles, selon des règles plus ou moins fines : tourniquet simple, nœud le moins chargé, affinité de session. Un serveur sature ? Le répartiteur l'évite. Il tombe ? Il l'écarte du circuit. Le client, lui, ne voit qu'une seule adresse.
Dans la pratique, le scale-out se décline en trois familles. Le tier applicatif sans état, le plus simple à multiplier. Les bases de données, par réplication ou par partition (le fameux sharding). Et les services distribués, où chaque brique scale de son côté. Trois terrains, trois niveaux de difficulté ; on y revient.
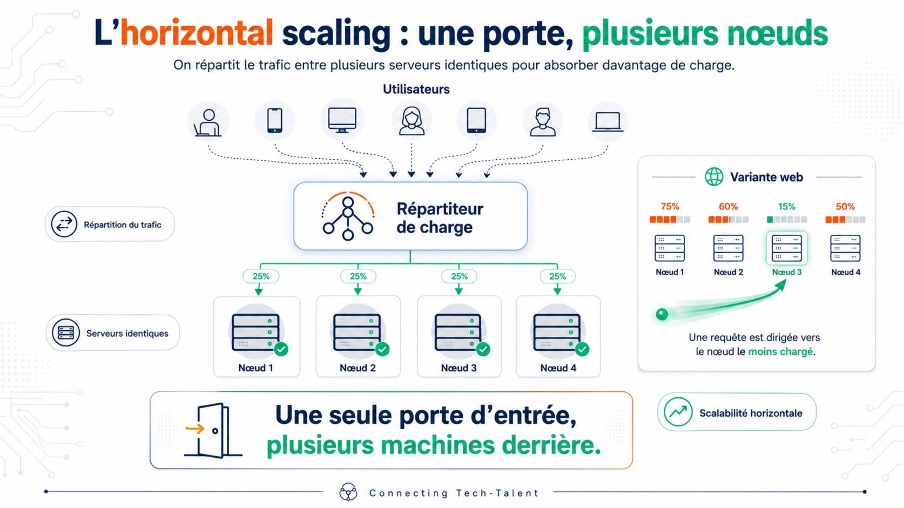
Les avantages du scaling horizontal
Premier atout, et pas le moindre : la haute disponibilité. Quand la charge se répartit sur plusieurs machines, la perte d'un nœud ne coupe pas le service. Les survivants absorbent, le répartiteur réoriente, l'utilisateur ne remarque rien. Là où le vertical mise tout sur une carte, l'horizontal joue collectif.
Deuxième atout : un plafond quasi illimité, doublé d'élasticité. Besoin de plus de puissance ? On ajoute des nœuds. Le pic retombe ? On en retire. Vous payez la capacité réellement consommée, pas un serveur surdimensionné qui dort les trois quarts du temps. Pour une charge en dents de scie, l'économie devient vite tangible.
Troisième atout : la résilience au sens large. Redondance native, déploiements sans coupure (on met à jour les nœuds un par un, en rolling update), capacité à encaisser une croissance qu'on n'avait pas vue venir. Autant de garanties que le vertical ne sait pas offrir.
Les limites du scaling horizontal

Tout ce confort a un prix, et le premier poste, c'est la complexité opérationnelle. Une machine, ça se surveille à l'œil. Une flotte, il faut l'orchestrer, la superviser, déployer dessus de façon coordonnée, gérer les versions qui cohabitent. Le métier change de nature : on ne pilote plus un serveur, on pilote un système.
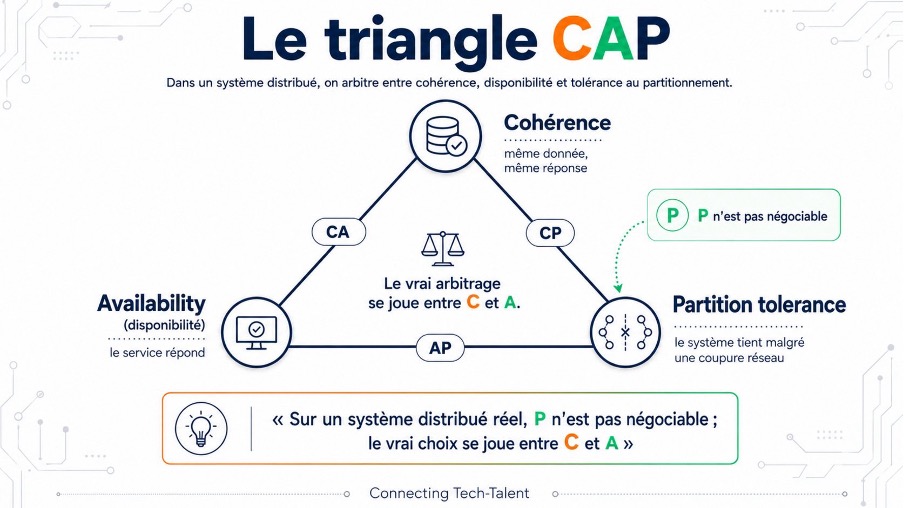
Vient ensuite le vrai casse-tête : la cohérence des données. Dès qu'on répartit l'état sur plusieurs nœuds, le théorème CAP rappelle sa loi. Entre cohérence, disponibilité et tolérance au partitionnement réseau, on n'en garde que deux. Pas de magie, pas de contournement : un arbitrage, qu'il faut assumer en connaissance de cause.
Le reste suit : latence réseau entre les nœuds, coût qui grimpe avec la flotte, et un debugging qui vire au cauchemar. Comment reproduire un bug qui ne surgit que sur un nœud, une requête sur mille, quand les horloges ne sont pas parfaitement synchrones ? Le distribué multiplie les surfaces de panne autant que les machines.
Les 8 sophismes du calcul distribué
Les fausses évidences qui font tomber les architectures naïves :
le réseau est fiable ;
la latence est nulle ;
la bande passante est infinie ;
le réseau est sûr ;
la topologie ne change jamais ;
il y a un seul administrateur ;
le coût de transport est nul ;
le réseau est homogène.
Votre architecture est-elle prête à scaler ?
Ajouter des nœuds ne sert à rien si l'application n'a pas été pensée pour. Pire : au premier serveur supplémentaire, elle casse. Avant de parler infrastructure, parlons readiness.
Une application vraiment prête au scale-out coche sept cases :
aucun état conservé en mémoire locale ;
sessions externalisées (cache distribué, pas la mémoire du nœud) ;
traitements idempotents ;
aucun fichier écrit sur le disque local ;
configuration externalisée, jamais en dur ;
logs centralisés, pas éparpillés sur chaque machine ;
healthchecks exposés pour le répartiteur.
Selon le nombre de cases cochées, votre architecture se range dans l'un de trois niveaux de maturité.

Les fautes classiques ? Stocker une session en mémoire du processus (l'utilisateur bascule de nœud, il est déconnecté).
Écrire un fichier sur le disque local (introuvable depuis les autres nœuds).
Mal régler l'affinité de session. Trois erreurs qui transforment un cluster flambant neuf en générateur de bugs aléatoires.
La base de données, le vrai point dur
On vous vend le scale-out comme une affaire de clonage de serveurs. C'est vrai pour le tier applicatif, et c'est précisément pour ça que la difficulté ne se loge pas là. Multiplier des serveurs web sans état ? Trivial. Multiplier une base de données ? On touche au nerf de la guerre !
Deux grandes réponses existent, et chacune résout un problème en en créant un autre. La réplication duplique les données sur plusieurs nœuds : parfaite pour distribuer les lectures, elle complique les écritures et pose la question de la cohérence entre copies.
Le sharding partitionne les données par clé sur des nœuds distincts : il distribue écritures comme lectures, mais rend les requêtes transversales et les transactions multi-shards franchement pénibles.
D'où l'essor des bases pensées dès l'origine pour le scale-out : le NoSQL distribué (MongoDB, Cassandra, Aerospike) et le NewSQL, qui cherchent à concilier distribution et garanties transactionnelles. Le relationnel classique scale aussi, mais il rame plus vite, et chaque palier se mérite.
Quand utiliser le scaling horizontal ?

Plusieurs signaux pointent franchement vers le scale-out ; un trafic en pics, imprévisible, qui réclame de l'élasticité. Un besoin de haute disponibilité où aucune coupure n'est tolérée. Une croissance forte ou incertaine. Un tier web déjà sans état, donc prêt à être multiplié sans douleur.
À l'inverse, le scaling horizontal complique pour rien dans d'autres contextes. Une charge modeste et stable ? Une seule bonne machine suffit. Une petite équipe sans bras pour exploiter une flotte ? La complexité coûtera plus qu'elle ne rapporte.
Comment mettre en œuvre le scaling horizontal ?
Le socle, c'est le couple répartiteur de charge plus autoscaling. On définit des règles de montée (au-delà de 70 % de CPU, on ajoute un nœud) et de descente (sous 30 %, on en retire un). L'infrastructure respire au rythme de la charge, sans intervention humaine.
Côté outillage, les conteneurs et l'orchestration règnent. Reste le point qui décide de tout : externaliser l'état proprement. Sessions dans un cache distribué (Redis, Memcached), fichiers dans un stockage objet, configuration centralisée.
Sans cette discipline, le plus bel autoscaling du monde ne fera que multiplier les incohérences.
Les modes de défaillance à grande échelle
Voici ce qu'on oublie de vous dire : scaler out crée des pannes qui n'existaient pas avant. Le distribué ne fait pas que diviser la charge, il invente de nouveaux scénarios de catastrophe.
Premier piège, l'effet thundering herd et les pannes en cascade. Un nœud sature et tombe ; sa charge se reporte sur les voisins, qui saturent à leur tour, qui tombent à leur tour. En quelques secondes, tout le cluster s'écroule comme une rangée de dominos. Le comble : c'est souvent le mécanisme de récupération mal calibré qui déclenche l'avalanche.
Deuxième piège, les pannes partielles. Un nœud sur dix ne tombe pas : il ment. Il répond, mais lentement, ou avec des données périmées. Plus sournois qu'une panne franche, parce que le répartiteur le croit en bonne santé et continue de lui envoyer du trafic.
Face à ce chaos, une trousse de secours s'impose. Sans elle, vous ne scalez pas, vous fabriquez une bombe à retardement distribuée.
Cas concret : une API web face à un pic de trafic
Imaginons : une API REST tourne tranquillement à 200 requêtes par seconde. Une campagne marketing la propulse à 5 000 requêtes par seconde sur trois jours. Faut-il surdimensionner en permanence, ou laisser l'autoscaling encaisser le pic ?
Le tier applicatif est sans état, donc le scale-out coule de source : on multiplie les nœuds derrière le répartiteur. Les chiffres ci-dessous donnent des ordres de grandeur, à affiner sur les grilles tarifaires du moment.

Avec l'autoscaling, vous payez 18 nœuds seulement pendant les heures de pic, puis vous redescendez à 3 une fois la campagne passée. En surdimensionnement permanent, vous payeriez 18 nœuds en continu, dont 15 inutiles 360 jours par an. Sur l'année, l'écart se chiffre en milliers d'euros.
Le verdict ? L'élasticité gagne, haut la main. Mais attention au coût caché qu’on oublie de provisionner : la montée en charge n'est pas instantanée. Démarrer un nœud prend des secondes, parfois des dizaines. Sans capacité tampon ni pré-chauffe, le pic vous passe dessus avant que la flotte n'ait fini de grandir.
FAQ sur l’horizontal scaling
Quelle différence entre scaling horizontal et vertical ?
Le vertical muscle une seule machine ; l'horizontal en ajoute plusieurs. Le premier est simple mais plafonne ; le second offre disponibilité et croissance quasi illimitée, au prix de la complexité.
Quels sont les avantages du scaling horizontal ?
Haute disponibilité, élasticité à la demande, plafond quasi illimité, redondance et déploiements sans coupure.
Quelles sont ses limites ?
Complexité opérationnelle, arbitrage CAP sur la cohérence des données, latence réseau, coût cumulé et debugging distribué.
Pourquoi une API doit-elle être sans état pour scaler ?
Parce qu'une requête peut atterrir sur n'importe quel nœud. Si l'état vit en mémoire d'un serveur précis, le moindre changement de nœud casse la session. Sans état, tous les nœuds deviennent interchangeables.
Quels sont les types courants de scale-out ?
Multiplication du tier applicatif sans état, réplication de bases pour les lectures, sharding pour les écritures, et services distribués où chaque brique scale indépendamment.
Le bon réflexe avant d'empiler les serveurs
Le scaling horizontal tient ses promesses : disponibilité, élasticité, croissance sans plafond visible. Mais il ne récompense que les architectures qui l'ont anticipé. Ajouter des machines à une application qui n'est pas prête ne fait que distribuer le désordre, et la vraie bataille se joue toujours sur la donnée, jamais sur le tier web. Avant de penser nombre de nœuds, mieux vaut se demander si l'application sait vivre à plusieurs, et si l'on a prévu de quoi tenir debout le jour où un nœud se met à mentir. Le scale-out ne sauve pas une fondation bancale ; il en révèle les fissures, à l'échelle.
👉 Le distribué, le cloud, l'orchestration vous parlent ? Ce sont exactement les compétences que les recruteurs recherchent. Sur Free-Work, repérez les missions et les postes qui valorisent vraiment ce savoir-faire, en CDI comme en freelance.







Commentaire
Connectez-vous ou créez votre compte pour réagir à l’article.