Le lexique de l’IA : comment un vocabulaire technique est entré dans le langage courant

On assiste à une étrange métamorphose du langage. Des mots autrefois confinés aux labos de Stanford ou aux articles d’ArXiv surgissent dans les daily meetings, les offres d’emploi, les specs techniques. Parfois bien employés, parfois totalement dévoyés. Mais une chose est sûre : le lexique de l’IA ne traverse pas simplement les murs de l’entreprise, il en modifie l’architecture mentale. Cet article propose un arrêt sur image — pour décrypter ce qui se dit, se diffuse et se transforme.
La mutation linguistique : comment le vocabulaire IA s’est diffusé hors des laboratoires

Des termes scientifiques aux usages mainstream
Algorithme, machine learning, neural network, LLM.
Quatre termes encore confidentiels il y a dix ans. Quatre piliers du vocabulaire courant en 2025.
Ce glissement n’a rien d’anodin. Il illustre une transformation culturelle où le lexique scientifique déborde des sphères R&D pour irriguer les médias, les entreprises et les échanges informels.
Dans les colonnes d’un quotidien généraliste, on parle désormais de « modèle entraîné » pour décrire un chatbot. Sur LinkedIn, le mot prompt s’utilise comme un outil de productivité. Même les utilisateurs non techniques adoptent ces mots, parfois sans en maîtriser les contours — mais avec une familiarité croissante.
Deux facteurs amplifient cette normalisation :
l’omniprésence des anglicismes (embedding, fine-tuning, inference),
l’acceptation progressive d’un « franglais technique » dans les communications internes, les offres d’emploi et les descriptions de poste.
Ce langage hybride fonctionne, car il comble une lacune : celle d’un vocabulaire français souvent trop académique ou imprécis face à des concepts émergents.
L’adoption massive de ces termes s’accélère avec la montée en puissance d’interfaces génératives accessibles comme ChatGPT, Midjourney ou Gemini.
Ces outils n’expliquent pas seulement ce qu’est un token ou un LLM — ils les incarnent, les font vivre dans l’expérience utilisateur.
Et quand une technologie devient manipulable à l’échelle individuelle, son vocabulaire suit le même chemin.
Pourquoi l’IA impose ses mots plus vite que les autres technologies
L’IA ne se contente pas de produire du contenu. Elle produit aussi du langage sur elle-même. C’est là que la viralité opère.
Dès qu’un terme entre dans un prompt, une vidéo explicative ou une discussion sur X/Twitter, il devient partageable. Même si personne ne l’a encore défini précisément.
Contrairement aux vocabulaires techniques classiques (cloud, conteneurisation, DevSecOps…), celui de l’IA repose sur des objets conversationnels.
Ce qui fait qu’un outil comme ChatGPT, par sa nature même, invite à manipuler des concepts : on teste une température, on compare un résultat avec ou sans mémoire, on apprend à formuler un zero-shot prompt…
L’utilisateur devient co-concepteur. Et, sans s’en rendre compte, il assimile une terminologie.
En résulte un effet de seuil : dès lors qu’un mot devient compréhensible par 20 % des utilisateurs, il se propage comme une convention implicite.
Le lexique IA suit donc une courbe virale, proche de celle des mêmes.
Les bases du lexique IA : les mots que tout le monde utilise aujourd’hui

Les termes grand public
IA, algorithme, modèle
Trois mots omniprésents. Trois significations mouvantes. Trois pièges lexicaux.
Le mot « IA » concentre à lui seul un malentendu de taille. Dans l’imaginaire collectif, il évoque des entités intelligentes, quasi conscientes, capables d’intuition, voire de raisonnement.
Cette vision anthropomorphique — largement nourrie par le cinéma, les médias et les interfaces conversationnelles — contraste radicalement avec la réalité technique : des modèles mathématiques, probabilistes, entraînés sur des volumes massifs de données, sans intention ni compréhension.
Même glissement sémantique pour le terme « algorithme », utilisé à toutes les sauces ! Tantôt accusé d’amplifier des biais, tantôt encensé pour sa performance, il finit par désigner tout mécanisme de décision automatique.
Dans les faits, un algorithme ne constitue qu’un ensemble d’instructions logiques. C’est une structure, pas une entité.
Quant au mot « modèle », il gagne en popularité à mesure que les utilisateurs interagissent avec des générateurs de texte ou d’image.
On parle d’un modèle pour désigner un LLM, une IA vocale, un système de recommandation. Le terme est juste, mais flou : il regroupe aussi bien des arbres de décision que des réseaux de neurones à plusieurs milliards de paramètres.
Chatbot, assistant, générateur

Ces trois-là passent souvent pour synonymes. À tort.
Un chatbot suit généralement des scénarios prédéfinis. Il propose des réponses issues d’une base figée, conçue pour limiter les branches possibles d’une conversation.
Un assistant — de type Siri, Alexa ou Google Assistant — combine plusieurs modules (NLP, reconnaissance vocale, moteur d’action) et se connecte à des services spécifiques.
Un générateur, enfin, repose sur un modèle de langage ou multimodal. Il produit du contenu neuf (texte, image, code, audio), à partir d’une consigne. Sa structure statistique ne repose pas sur une arborescence, mais sur un espace vectoriel de probabilité.
Tout système qui répond par écrit n’est donc pas un chatbot.
Et tout chatbot n’a pas la souplesse d’un assistant conversationnel dopé aux LLM.
L’imprécision du vocabulaire cache souvent une confusion sur le niveau d’autonomie, le type de modèle et la nature des réponses.
Les termes popularisés par l’IA générative
L’explosion des interfaces comme ChatGPT ou Midjourney a fait basculer certains mots dans la sphère publique. Des termes techniques, autrefois réservés aux chercheurs ou aux ingénieurs, circulent aujourd’hui entre des managers, des recruteurs, des graphistes, des équipes RH.
Voici ceux qui dominent la conversation.
Prompt : Une simple consigne en apparence. En réalité, une commande textuelle structurée, transmise à un modèle pour produire une sortie (texte, image, code, etc.). Sa formulation influe directement sur la qualité, le ton et la pertinence de la réponse. Le prompt devient une compétence en soi.
Hallucination : Non, le modèle ne délire pas. Il prédit une suite de tokens qui semble plausible mais factuellement fausse. L’expression est imagée, presque trompeuse : elle donne l’impression que l’IA voit ou interprète la réalité, ce qui n’a jamais lieu. Une hallucination relève d’un échec statistique, pas d’un bug ni d’un mensonge.
Le lexique professionnel : les mots qui structurent les échanges dans les métiers IT
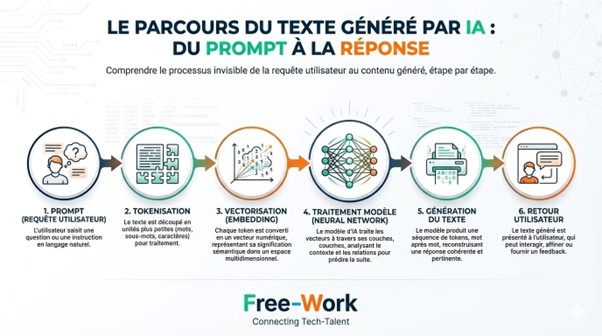
Même sans formation académique en IA, les pros de la Tech croisent régulièrement ces notions :
Dataset, features, labels : Le dataset constitue la base d’entraînement. Les features décrivent les caractéristiques extraites. Les labels servent d’objectif à prédire. Ce triptyque forme la base de tout apprentissage supervisé.
Entraînement, validation, test : Trois phases, trois objectifs. L’entraînement ajuste les paramètres. La validation évalue les performances sur des données non vues. Le test mesure la robustesse finale du modèle.
Embeddings : Représentations vectorielles d’un mot, d’une phrase, d’un document. L’embedding encode le sens de manière géométrique : deux idées proches dans le langage sont proches dans l’espace vectoriel.
Loss function : Elle mesure l’écart entre ce que le modèle prédit et la vérité attendue. Une bonne loss guide l’optimisation. Une mauvaise perte oriente le modèle dans la mauvaise direction.
Le vocabulaire génératif désormais présent en entreprise
Token : Plus petit élément traité par un modèle. Un mot ? Pas toujours. Le mot « multicloud » peut compter pour un seul token ou plusieurs, selon le tokenizer utilisé.
Fenêtre contextuelle (context window) : Elle délimite la quantité d’information que le modèle peut traiter dans une seule séquence. Une limite technique aux ambitions conversationnelles.
Fine-tuning, RAG : Le fine-tuning modifie les poids d’un modèle existant à partir d’un jeu de données ciblé. Le RAG combine un moteur de recherche interne et un LLM : il injecte des contenus précis dans le contexte au moment de la génération.
Vous cherchez une offre d'emploi ou de mission en IA ?
Un langage qui façonne les usages : ce que révèle le lexique IA sur notre rapport à la technologie

Quand le vocabulaire façonne la perception
Les mots ne décrivent pas toujours la réalité. Ils la dessinent, parfois à contre-sens.
Reprenons le terme « hallucination ». Le modèle ne rêve pas. Il ne projette rien. Il calcule.
Mais l’image mentale induite par ce mot crée un biais cognitif : on imagine un être « doté d’une conscience « qui déraille. En réalité, l’erreur résulte d’une probabilité mal ajustée dans un espace vectoriel.
Même dérive avec le mot : intelligence, qui constitue l’énorme malentendu du siècle. Les systèmes d’IA ne raisonnent pas. Ils ne comprennent pas. Ils anticipent des séquences. Leur intelligence relève d’une capacité prédictive, pas d’un processus mental.
Le mot, pourtant, persiste. Il crée un écart entre ce que les utilisateurs croient activer… et ce que les systèmes font réellement.
Les risques d’un lexique mal compris
La confusion ne relève pas seulement de la sémantique. Elle entraîne des effets opérationnels tangibles.
Dans les entreprises, une surestimation des capacités IA conduit à des erreurs d’évaluation.
On attribue à des modèles des compétences cognitives qu’ils ne possèdent pas. On parle d’analyse, de compréhension, de réflexion. Ce glissement mène à des implémentations hâtives, mal calibrées, déconnectées de la réalité statistique.
À l’inverse, les enjeux techniques — eux — passent souvent à l’arrière-plan.
Le drift des données ? Peu évoqué.
Les failles de sécurité ? Reléguées aux équipes techniques.
La question de la souveraineté technologique ? Rarement posée lors du choix d’un LLM propriétaire.
Un vocabulaire flou entraîne des décisions floues.
Lexique synthétique : 50 définitions classées du plus courant au plus technique
1️⃣Langage courant
IA : Ensemble de techniques permettant à des systèmes informatiques de simuler certaines fonctions cognitives humaines.
Algorithme : Suite logique d'instructions conçues pour résoudre un problème ou exécuter une tâche.
Modèle : Structure mathématique entraînée sur des données pour produire des prédictions ou du contenu.
Assistant : Interface logicielle, souvent conversationnelle, facilitant l’interaction avec un système.
Hallucination : Réponse fausse ou inventée générée par un modèle, formulée de manière crédible.
Image générée : Visuel produit à partir d’un prompt par un modèle de génération d’image.
Deepfake : Falsification réaliste de contenus audio ou vidéo à l’aide de techniques d’IA.
Agent conversationnel : Entité logicielle simulant un rôle ou une personnalité dans une interaction textuelle.
2️⃣Base technique
Dataset : Ensemble de données utilisé pour entraîner, valider ou tester un modèle.
Features : Variables descriptives extraites des données pour nourrir un modèle prédictif.
Labels : Résultats attendus associés à chaque entrée dans un apprentissage supervisé.
Training : Processus d’ajustement des paramètres d’un modèle à partir de données étiquetées.
Validation set : Jeu de données servant à mesurer la performance d’un modèle en cours d’entraînement.
Test set : Données finales utilisées pour évaluer la généralisation d’un modèle.
Loss function : Fonction calculant l’écart entre les prédictions du modèle et les résultats attendus.
Embedding : Représentation vectorielle dense d’un mot, document ou image dans un espace numérique.
Batch size : Nombre d’exemples traités simultanément lors d’une étape d’apprentissage.
3️⃣IA générative
Prompt : Instruction textuelle envoyée à un modèle pour générer une réponse ciblée.
Token : Unité de texte manipulée par le modèle, correspondant à un mot ou un fragment de mot.
Fenêtre contextuelle : Quantité maximale de tokens qu’un modèle peut prendre en compte dans une requête.
Top-k / Top-p sampling : Méthodes contrôlant la sélection de mots en sortie selon leur probabilité.
Temperature : Paramètre ajustant le niveau d’aléatoire dans la génération de texte.
RAG : Technique combinant un moteur de recherche et un modèle génératif pour injecter du contexte en temps réel.
Fine-tuning : Spécialisation d’un modèle existant à l’aide d’un jeu de données ciblé
Chain-of-thought prompting : Formulation guidée d’un prompt en plusieurs étapes logiques successives.
Multi-turn memory : Capacité d’un modèle à conserver l’historique d’une conversation sur plusieurs échanges.
4️⃣Production & MLOps
Latence d’inférence : Délai entre l’envoi d’une requête et la réponse générée par le modèle.
Data drift : Évolution des données en production par rapport à celles d’entraînement, affectant les performances.
Modèle non déterministe : Système produisant des résultats variables à chaque exécution avec les mêmes entrées.
Observabilité : Ensemble des outils et métriques permettant de suivre le comportement d’un modèle en production.
Pipeline ML : Chaîne automatisée regroupant l’entraînement, la validation, le déploiement et la supervision d’un modèle.
Model registry : Répertoire versionné centralisant les modèles entraînés et déployés.
Serving : Mise à disposition d’un modèle via une API pour une utilisation en production.
Rollback : Restauration d’une version antérieure d’un modèle suite à une dérive ou à une erreur critique.
5️⃣Architecture & sécurité
Transformer : Architecture de réseau neuronal basée sur le mécanisme d’attention, utilisée dans les LLM.
Attention : Mécanisme permettant à un modèle de pondérer l’importance de chaque élément d’entrée selon son contexte
LoRA : Technique de fine-tuning partiel permettant d’adapter un modèle avec un faible coût computationnel.
Mixture of Experts : Architecture distribuée activant dynamiquement différents sous-modèles selon l’entrée.
Quantization : Réduction de la précision des poids pour alléger et accélérer un modèle.
Vector DB : Base de données optimisée pour la recherche par similarité dans des espaces d’embeddings.
Jailbreak : Contournement des limites imposées à un modèle via des prompts spécifiques.
Red teaming IA : Ensemble de tests offensifs visant à identifier les failles et dérives d’un modèle.
XAI : Approches rendant les décisions d’un modèle compréhensibles pour les utilisateurs humains.
6️⃣Usages & métiers IT
Prompt engineering : Élaboration optimisée de prompts pour obtenir des résultats fiables et pertinents.
Guided generation : Génération encadrée par des contraintes syntaxiques, logiques ou de format.
Co-pilotage de code : Assistance à l’écriture de code par un outil d’IA intégré à l’environnement de développement.
Test automation IA : Génération automatique de cas de test à partir de spécifications ou de code source.
Data observability : Surveillance active de la qualité, de la fraîcheur et de la cohérence des données.
Bias detection : Détection des biais implicites dans les prédictions d’un modèle d’IA.
Souveraineté technologique : Capacité à maîtriser ses infrastructures et modèles IA sans dépendre d’acteurs externes.








Commentaire
Connectez-vous ou créez votre compte pour réagir à l’article.