Comment mesurer la qualité de son code ?

Un indicateur rassure. Une métrique structure. Mais aucune ne raconte, à elle seule, la réalité d’une base de code. La qualité se construit dans l’équilibre : entre complexité maîtrisée, lisibilité durable et capacité à évoluer sans tout réécrire. Dès lors, mesurer la qualité du code suppose davantage qu’un outil ou un score. Il faut comprendre ce que l’on mesure, pourquoi on le mesure, et comment ces signaux guident des choix techniques durables.
Que recouvre réellement la qualité du code ?

La qualité du code ne se résume ni à une indentation soignée ni à l’absence de warnings dans un pipeline CI. Elle renvoie à un ensemble de propriétés techniques, souvent entremêlées, qui conditionnent la capacité d’un système à durer, évoluer et encaisser la contrainte sans se déformer.
Qualité du code : une notion multidimensionnelle, bien au-delà de la « propreté »
Réduire la qualité du code à un critère esthétique conduit rapidement dans une impasse. En effet, un code lisible mais fragile en production ne tient pas. Un code performant mais illisible non plus.
En réalité, la qualité s’exprime dans un équilibre subtil entre plusieurs dimensions, qui ne progressent pas toujours de concert.
On retrouve notamment :
La lisibilité, qui conditionne la compréhension rapide d’une intention métier ou technique.
La maintenabilité, soit la capacité à modifier le code sans générer d’effets de bord imprévus.
La robustesse, qui traduit la résistance aux cas limites, aux entrées inattendues et aux usages déviants.
La testabilité, souvent révélatrice de la qualité de la conception en amont.
La sécurité, indissociable des choix d’architecture et de gestion des dépendances.
La performance, non pas comme une obsession, mais comme une propriété maîtrisée et mesurée.
Ces dimensions ne parlent pas toutes le même langage. Certaines relèvent du ressenti développeur — clarté, élégance, cohérence interne.
D’autres se manifestent côté exploitation — incidents, latence, scalabilité, coûts d’infrastructure.
Cette distinction éclaire une fracture fréquente : la qualité perçue, vécue au quotidien par les équipes de développement, face à la qualité opérationnelle, observée par le run, le produit ou le business.
Un code peut « fonctionner ». Passer les tests. Livrer la feature attendue. Et pourtant rester de mauvaise qualité. Trop complexe pour évoluer sereinement. Trop couplé pour absorber une nouvelle contrainte. Trop opaque pour survivre à un changement d’équipe.
De facto, la qualité ne se juge pas uniquement à l’instant T, mais à la trajectoire qu’elle autorise.
Any fool can write code that a computer can understand. Good programmers write code that humans can understand. – Martin Fowler
Pourquoi mesurer la qualité du code devient critique à l’échelle des organisations ?

À petite échelle, l’intuition et l’expérience compensent parfois l’absence d’indicateurs. Mais, à mesure que les systèmes grandissent, cette approche montre rapidement ses limites.
Les bases de code s’étendent, se fragmentent, se superposent. Monolithes historiques. Microservices hétérogènes. Scripts périphériques devenus centraux...
Par ailleurs, le turnover accélère. Les équipes changent. L’onboarding absorbe un temps croissant. Chaque départ emporte avec lui une part de contexte implicite. La dette n’est plus seulement technique ; elle devient cognitive.
Comprendre « pourquoi » prend autant de temps que comprendre « comment ».
Les conséquences se manifestent inéluctablement :
Le time-to-market s’allonge, faute de confiance dans la capacité à modifier sans casser.
La fiabilité en production se dégrade, les incidents révélant des fragilités enfouies depuis longtemps.
L’attractivité employeur en pâtit, car une base de code difficile à appréhender dissuade durablement les profils expérimentés.
Mesurer la qualité du code ne relève alors plus d’une démarche d’amélioration marginale. Il s’agit d’un levier de pilotage.
Vous cherchez un poste de développeur ?

Les grandes familles de métriques pour mesurer la qualité du code

1️⃣ Les métriques structurelles ou comment mesurer la complexité interne du code
La complexité structurelle décrit la manière dont le code s’organise en interne. Elle ne préjuge ni du métier ni de la valeur fonctionnelle, mais elle conditionne directement la compréhension, la modification et la robustesse globale.
Plusieurs signaux à prendre en compte :
La complexité cyclomatique, qui comptabilise le nombre de chemins d’exécution indépendants dans une fonction ou une méthode.
La profondeur d’imbrication, révélatrice d’une logique conditionnelle difficile à suivre.
La taille des fonctions et des classes, souvent corrélée à une responsabilité mal définie.
Le couplage et la cohésion, qui indiquent dans quelle mesure les composants dépendent les uns des autres ou, a contrario, poursuivent un objectif clair.
Une confusion persiste toutefois entre deux notions proches, mais distinctes. La complexité cyclomatique mesure une réalité mathématique : le nombre de branches possibles. La complexité cognitive, elle, reflète l’effort mental nécessaire pour comprendre le code.
Une fonction courte, mais truffée de conditions imbriquées et de ruptures de flux, peut rester cognitivement lourde malgré une cyclomatique modérée. A contrario, un algorithme long mais linéaire conserve parfois une lisibilité acceptable.
Les seuils d’alerte ne relèvent jamais d’une règle universelle. Sur un projet greenfield, une complexité cyclomatique supérieure à 10 justifie souvent une alerte immédiate. Sur un legacy critique, ce seuil perd de sa pertinence. Le contexte, la criticité métier et l’historique du code modulent nécessairement l’interprétation.

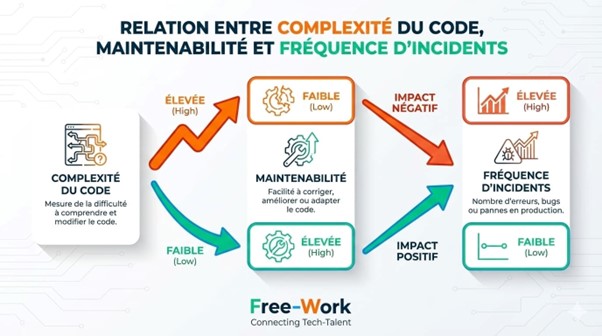
2️⃣ Les métriques de maintenabilité et d’évolutivité

La maintenabilité se manifeste rarement par une panne franche. Elle s’érode. Progressivement. Chaque modification coûte un peu plus cher que la précédente. Les métriques associées cherchent précisément à objectiver cette dérive.
Le Maintainability Index synthétise plusieurs signaux structurels en un score global. Il ne raconte pas toute l’histoire, mais il facilite la comparaison dans le temps ou entre modules.
La duplication de code complète cette lecture : plus un comportement se répète, plus la correction devient risquée. Une anomalie corrigée à un endroit persiste ailleurs.
La dette technique estimée, proposée par certains outils, matérialise l’effort nécessaire pour revenir à un niveau de qualité cible. Cette estimation reste imparfaite, mais elle fournit un ordre de grandeur utile dans les arbitrages.
Enfin, la fréquence et le coût des modifications livrent un indicateur terrain, directement observable par les équipes.
3️⃣ Les métriques de fiabilité et de robustesse
Un code robuste ne se contente pas de fonctionner dans un scénario nominal. Il encaisse les usages imprévus, les entrées dégradées et les charges inhabituelles. Les métriques de fiabilité s’observent souvent à la frontière entre développement et exploitation.
La densité de bugs par module, par exemple, met en lumière des zones fragiles. La fréquence des incidents liés au code révèle, quant à elle, des faiblesses structurelles plus profondes. Le Mean Time To Failure (MTTF) complète cette lecture en mesurant la durée moyenne de fonctionnement avant incident.
La couverture des cas limites reste plus difficile à quantifier, mais elle s’apprécie via l’analyse des incidents passés et des scénarios de test absents. Les pratiques SRE, popularisées par Google, insistent sur cette continuité entre qualité du code et fiabilité perçue en production.
4️⃣ Les métriques de testabilité et de vérification
La testabilité agit comme un révélateur. Un code difficile à tester signale souvent une conception trop couplée ou trop rigide. Les métriques associées vont bien au-delà d’un « simple pourcentage ».
La couverture de tests se décline en plusieurs niveaux : lignes, branches, mutations. Le temps d’exécution des tests influe directement sur la discipline d’intégration continue. Le ratio entre tests unitaires, d’intégration et end-to-end renseigne sur la granularité de la stratégie de vérification.
Un piège à éviter : la couverture seule rassure, mais trompe souvent. Un taux élevé n’empêche ni les tests superficiels ni l’absence de scénarios critiques.
Le mutation testing met en lumière cette limite en évaluant la capacité réelle des tests à détecter des défauts introduits artificiellement.
5️⃣ Les métriques de sécurité applicative liées au code
La sécurité ne doit pas en bout de chaîne. Elle s’inscrit dans les choix de code, de dépendances et de conception. Les métriques associées traduisent cette réalité.
Les vulnérabilités connues, référencées via les CWE ou l’OWASP Top 10, constituent un premier niveau d’analyse. L’analyse statique de sécurité (SAST) détecte des patterns dangereux directement dans le code source. L’examen des dépendances à risque complète ce dispositif, les failles transitant fréquemment par des bibliothèques tierces.

La lecture croisée entre mauvaises pratiques de code et failles connues accélère la priorisation. Une injection SQL ou une désérialisation non sécurisée ne relève jamais d’un simple oubli ; elle révèle un défaut structurel.
Quels outils pour mesurer la qualité du code efficacement ?
Les métriques seules ne produisent aucun effet. Sans outillage, elles restent théoriques. Les outils de mesure de la qualité du code prennent tout leur sens lorsqu’ils s’inscrivent dans un dispositif cohérent, adapté au contexte technique et au niveau de maturité des équipes.
Analyse statique automatisée
L’analyse statique inspecte le code sans l’exécuter. Elle passe au crible la structure, les dépendances, les conventions et certains patterns à risque. Bien configurée, elle agit comme un garde-fou permanent.
Des outils dominent largement cet espace, chacun avec ses spécificités :
SonarQube, orienté pilotage global, dette technique et suivi dans le temps.
ESLint, Pylint, PMD, Checkstyle, plus proches du développeur, intégrés à l’IDE ou au pipeline CI.
Des analyseurs spécialisés selon les langages ou les frameworks, souvent plus fins sur des règles ciblées.
L’analyse statique excelle dans la détection précoce : duplications, complexité excessive, conventions non respectées, failles évidentes. En revanche, elle ignore le contexte métier, la pertinence fonctionnelle et certaines subtilités d’exécution. Un score élevé ne garantit ni lisibilité réelle ni conception saine.
Checklist — Configuration minimale recommandée
Activer les règles de complexité et de duplication
Définir des seuils progressifs, jamais bloquants au départ
Bloquer uniquement les failles critiques et la dette nouvelle
Rendre les rapports visibles par toute l’équipe
Analyse dynamique et observabilité du code en production
Le code ne révèle jamais toute sa réalité hors production. Une base lisible peut se comporter de manière erratique sous charge. À l’inverse, un code dense, mais maîtrisé, peut afficher une stabilité remarquable. L’analyse dynamique comble ce décalage.
Les outils d’APM instrumentent l’exécution réelle : latence, erreurs, consommation mémoire, saturation. Ils relient directement le comportement observé aux chemins de code empruntés. Cette corrélation éclaire des zones jusqu’alors invisibles.
Les logs, traces distribuées et métriques applicatives peuvent aussi agir comme des signaux faibles ; une explosion de logs d’erreur, une trace anormalement longue, une métrique instable racontent souvent une histoire de conception fragile, bien avant un incident majeur.
Des plateformes comme New Relic ou Datadog, couplées à OpenTelemetry, structurent cette observabilité. Elles replacent la qualité du code dans son contexte réel : celui des usages, des charges et des contraintes opérationnelles.
Revue de code : mesure qualitative indispensable
Aucun outil automatisé ne remplace le regard humain. La revue de code ne sert pas à traquer des fautes de syntaxe déjà couvertes par les linters. Elle vise autre chose. Beaucoup plus structurant.
Une revue efficace questionne :
la clarté de l’intention,
la cohérence avec l’architecture existante,
la capacité du code à évoluer sans friction,
la lisibilité pour un tiers absent du contexte initial.
Des critères concrets guident cette lecture : nommage, découpage, responsabilité des composants, gestion des erreurs, couverture des cas limites... La valeur se niche dans la discussion, pas dans l’approbation mécanique.
Mesurer la qualité du code du point de vue des compétences et de l’employabilité

La qualité du code ne concerne pas uniquement le produit. Elle raconte aussi une histoire humaine. Celle des compétences, de la culture d’ingénierie et, in fine, de la valeur perçue sur le marché.
Qualité du code et maturité des équipes
Un repository agit comme un révélateur. En quelques heures, il expose le niveau technique dominant, la rigueur collective et la capacité à travailler à plusieurs sans chaos.
Un codebase lisible, cohérent et bien testé traduit souvent :
des développeurs à l’aise avec la conception,
une culture de revue et de feedback,
une organisation capable d’absorber la croissance sans tout réécrire.
À l’inverse, une accumulation de solutions ad hoc, de duplications et de contournements signale une dette plus profonde. Non pas un manque de talent individuel, mais une maturité d’équipe insuffisante.
La qualité du code comme signal fort pour les recruteurs et freelances
Les recruteurs techniques lisent rarement un CV sans chercher des preuves concrètes. Un repository public, un extrait de code ou un projet open source pèsent souvent davantage qu’une stack à la mode.
La qualité du code informe sur :
la capacité à raisonner au-delà du framework,
la maîtrise des compromis techniques,
l’aptitude à travailler dans des environnements complexes.
De facto, elle influence directement la crédibilité technique, le TJM ou le niveau de rémunération, ainsi que l’attractivité sur des plateformes spécialisées comme Free-Work, où la concurrence repose sur la valeur perçue plus que sur les mots-clés.
Intégrer la qualité du code dans une stratégie de carrière IT ?
Choisir des environnements exigeants, valoriser des contributions structurantes, documenter des décisions de conception dans un portfolio technique sont susceptibles de changer durablement la perception d’un profil.
En entretien, certaines questions font la différence : comment l’équipe mesure-t-elle la dette ? Comment la revue de code fonctionne-t-elle ? Comment la qualité influe-t-elle sur les arbitrages produit ?
La qualité du code devient alors un levier stratégique. Pas un supplément d’âme. Un marqueur de maturité, visible, durable, différenciant.
Mesurer la qualité du code sans perdre de vue l’essentiel
La qualité du code ne se laisse jamais enfermer dans un score unique ni dans un dashboard flatteur. Elle forme un système vivant, composé de structures, de pratiques, de choix techniques et de comportements collectifs. Isoler une métrique sans relier les autres revient à observer une pièce du mécanisme en ignorant l’engrenage complet.
Mesurer conserve néanmoins tout son sens. À une condition. La mesure doit servir la décision. Orienter un refactoring. Prioriser une dette. Sécuriser une évolution. Améliorer la collaboration entre équipes.
Lorsque les indicateurs cessent de nourrir l’action, ils se transforment en bruit. À l’inverse, bien interprétés, ils structurent une démarche d’amélioration continue, pragmatique, alignée sur les enjeux techniques et organisationnels.







Commentaire
Connectez-vous ou créez votre compte pour réagir à l’article.