Self-Healing Software : quand le code apprend à survivre tout seul

Les machines ne dorment pas. Elles s’épuisent, plantent, repartent, mais elles ne dorment pas. Et si certaines ne demandaient plus jamais de l’aide ? Pas de ticket Jira, pas d’astreinte en pleine nuit : elles identifient la panne, la résorbent, puis reprennent leur service comme si rien ne s’était produit. Ce n’est pas de la magie, c’est du self-healing - et cela change complètement la façon d’écrire, d’observer et d’opérer nos systèmes.
Avant de rentrer dans le code : qu’entend-on vraiment par « self-healing software » ?

Le terme circule de plus en plus dans les conférences, les docs produit, les specs d’architectes cloud. Pourtant, il ne décrit pas toujours la même réalité.
Un self-healing software (ou application) désigne une application capable de détecter une anomalie et de déclencher seule une action corrective. Pas besoin d’intervention humaine, pas de redéploiement manuel.
À un niveau plus large, le self-healing system englobe toute l’infrastructure ou l’écosystème logiciel — orchestrateurs, pipelines CI/CD, load balancers, bases de données — qui participent à cette auto-réparation.
Quant à l’auto-remédiation, elle correspond à l’exécution d’actions prédéfinies lorsqu’un incident survient : script Bash, playbook Ansible, redéploiement Kubernetes… bref, un correctif, mais pas toujours intelligent, ni adaptatif.
Pour mieux visualiser, une analogie fonctionne particulièrement bien : penser l’application comme un organisme vivant.
Le monitoring joue le rôle des capteurs nerveux.
L’anomalie s’apparente à une blessure.
La remédiation agit comme la cicatrisation ou le système immunitaire qui neutralise la menace.
Avant de parler d’auto-guérison, l’industrie logicielle ne rêvait que de tolérance aux pannes (fault tolerance). L’objectif consistait à absorber l’erreur, pas à la corriger. Puis IBM introduit au début des années 2000 le concept d’autonomic computing : des systèmes qui s’autogèrent, un peu comme le système nerveux autonome humain.
L’évolution continue :
DevOps rapproche le code et l’exploitation.
Cloud natif introduit la scalabilité et l’éphémère comme paradigme standard.
Kubernetes automatise le déploiement et la résurrection des conteneurs.
AIOps injecte l’apprentissage automatique dans l’observabilité pour détecter des anomalies sans règle écrite.
Comment un logiciel apprend à se réparer : architecture et coulisses
La boucle MAPE-K : le cerveau du self-healing
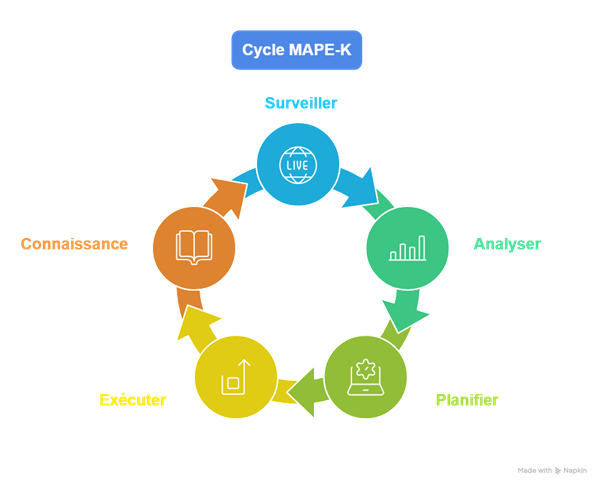
Dans presque toutes les implémentations sérieuses, un modèle revient : MAPE-K, issu de l’autonomic computing. Il se décompose ainsi :
Monitor : collecter des signaux — CPU, latence, logs d’erreur, métriques SLO.
Analyze : identifier les anomalies, repérer une dérive ou un comportement incongru.
Plan : choisir une stratégie de correction (redémarrage, scaling, rollback…).
Execute : déclencher l’action corrective.
Knowledge : base de connaissances, historique, patterns, modèles ML.
Tous les systèmes auto-réparateurs ne jouent pas dans la même catégorie
Il existe plusieurs niveaux de maturité. En caricaturant à peine, voici la hiérarchie :
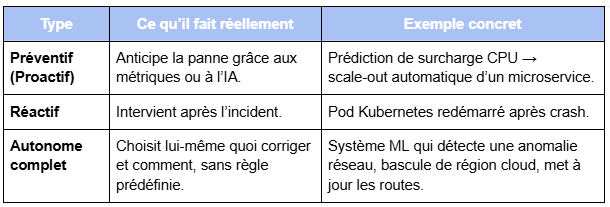
Ce troisième niveau reste rare. Il implique des modèles prédictifs, des scenarii de résilience testés à l’avance, voire des décisions non prescrites par les développeurs.
Quand tout casse, comment le système agit concrètement ?
Un self-healing opérationnel ne se limite pas à redémarrer un service. Plusieurs stratégies se combinent :
Redémarrage automatique : service, pod, VM, container.
Rollback ou roll-forward : retour immédiat à une version stable, ou déploiement d’un correctif.
Auto-scaling et respawn de conteneurs : Kubernetes supprime un pod défaillant, réplique un nouveau, rééquilibre la charge.
Self-healing applicatif vs infrastructure :
Côté applicatif : gestion d’erreurs intelligente, retry, fallback, timeout.
Côté infra : RestartPolicy Kubernetes, autoscaling groups AWS, scripts Terraform ou Ansible.
Dès lors, l’auto-guérison ne repose pas uniquement sur la technologie mais sur une philosophie : construire des systèmes qui acceptent l’échec et savent se relever.
Avantages, limites et défis actuels

Pourquoi le self-healing séduit autant les équipes tech
Dès qu’un incident survient, chaque minute compte. Dans une architecture distribuée, une panne mineure peut se transformer en cascade d’erreurs.
Le self-healing ambitionne de réduire drastiquement le MTTR (Mean Time To Repair) : le système agit avant que l’alerte n’arrive dans Slack ou PagerDuty. Résultat : moins de nuits passées à relancer des pods en urgence, moins d’astreintes inutiles.
Cette automatisation désengorge les équipes SRE et DevOps. Elles ne passent plus leurs journées à éteindre des incendies, mais à améliorer l’observabilité, optimiser des pipelines, renforcer l’architecture. C’est un changement de posture : moins d’opérationnel réactif, davantage d’ingénierie proactive.
Financièrement, le gain se ressent aussi :
moins d’interruptions de service, donc des SLA respectés ;
moins de coûts d’exploitation, car chaque correctif n’exige pas l’attention d’un humain ;
plus de résilience naturelle, même lors de pics imprévus.
Les limites techniques qu’on oublie souvent de mentionner
Le self-healing n’a rien d’un bouton magique. Derrière chaque réparation automatique, il existe des feedback loops qui collectent, analysent, décident, agissent… et ces boucles deviennent vite complexes à maintenir.
Une règle ou un seuil mal configuré provoque des comportements absurdes : restart infinis, scaling incontrôlé, suppression de services encore sains.
Autre écueil : les faux positifs. Le système interprète un pic de latence comme une panne, applique une correction inutile, voire nocive. Dans certains cas, la remédiation crée un problème plus grave que l’incident initial : rollback inadapté, perte de sessions utilisateur, corruption de données.
Enfin, il ne faut pas sous-estimer le coût d’implémentation. Construire un self-healing fiable implique :
une observabilité avancée,
des métriques cohérentes et exploitables,
des scripts ou modèles d’IA testés, documentés, sécurisés.
Et maintenant, les vraies questions : éthique, responsabilité, confiance
Plus les systèmes se réparent sans supervision, plus une question revient : qui garde la main ? Une plateforme qui modifie sa propre infrastructure, redéploie des services, applique un correctif critique… agit sans validation humaine. Jusqu’où accepter qu’un logiciel prenne ce type de décision ?
Cette autonomie pose aussi un sujet juridique : qui porte la responsabilité lorsqu’une remédiation automatique aggrave un problème ? L’équipe SRE ? Le développeur qui a écrit le script ? Le modèle d’IA ? Le fournisseur cloud ?
Dernier point, souvent sous-estimé : l’auditabilité. Dans un système auto-cicatrisant, chaque action doit laisser une trace claire. Il faut pouvoir remonter la chaîne de décision, comprendre pourquoi le système a choisi de redémarrer un service, purger un cache ou rerouter le trafic. Sans cette transparence, impossible d’établir la confiance.
Self-healing appliqué aux tests automatisés : moins de scripts cassés, plus de robustesse

Les tests end-to-end cassés pour un bouton déplacé dans le DOM, tout le monde y a goûté. Le self-healing transforme ce cauchemar quotidien. Exemples :
Localisation dynamique des sélecteurs
Un test Selenium échoue parce qu’un ID a changé ? Le système compare l’ancienne version de l’interface avec la nouvelle, retrouve l’élément via d’autres attributs (texte, structure XPath, pattern visuel) et met à jour le script automatiquement.
Réécriture automatique des tests défaillants
Des frameworks comme Healenium ou Testim interceptent l’erreur, adaptent le locator et stockent la nouvelle version dans un repository Git. Les tests cessent de se comporter comme du code jetable.
Perspectives futures

Et si l’IA générative écrivait un code qui se corrige lui-même ?
Demain — ou presque — un pipeline pourrait fonctionner ainsi : l’IA générerait du code, lancerait automatiquement les tests, analyserait les erreurs, corrigerait le code… et recommencerait jusqu’à obtenir un build stable.
Les modèles type GPT ou CodeLlama joueraient déjà ce rôle partiellement.
La boucle complète d’écriture → test → réparation resterait expérimentale, mais elle pourrait devenir la fondation du self-healing appliqué au développement lui-même.
SHaaS : Self-Healing as a Service - un futur modèle de cloud ?
Et si le cloud ne se contentait plus d’héberger des workloads mais proposait nativement :
un monitoring avancé,
une décision automatisée basée sur IA,
des remédiations prêtes à l’emploi ?
Des plateformes comme AWS, Azure ou GCP pourraient fournir un service « plug-and-run » : déposez vos microservices, la plateforme surveille, apprend, répare.
Aujourd’hui, ce scénario reste fragmenté, mais il pourrait représenter la prochaine étape après les managed Kubernetes et l’AIOps.
Vers des systèmes entièrement autonomes ?
Certains chercheurs évoquent déjà un futur où le logiciel ne se contenterait plus de se réparer, mais évoluerait pour éviter la récidive.
Création de variantes de code adaptées à un incident donné.
Sélection naturelle des architectures les plus stables.
Écosystèmes logiciels auto-régulés, inspirés des systèmes biologiques.
On parlerait alors non plus de « maintien en condition opérationnelle », mais de logiciels vivants, capables de muter, de s’adapter, et peut-être de s’organiser sans supervision constante.
Rien de tout cela n’existe à l’échelle industrielle, mais les premiers signaux apparaissent dans la recherche IA et la simulation d’environnements autonomes.







Commentaire
Connectez-vous ou créez votre compte pour réagir à l’article.